I hold a PhD in Computer Science (specialisation on Big Data, Data Visualisation & Human-Computer Interaction) from the University of Southampton. My thesis focused on how to develop novel methods of interaction and interfaces that allowed users to explore, navigate and query big graph datasets. Below are some of the projects as part of my research. You can find a list of my research publications here.
Back
mashpoint
mashpoint is a framework that allows data rich apps to be connected based on similar entities in their data. By linking applications in this way we can browse the Web in a data-centric way.
Publications

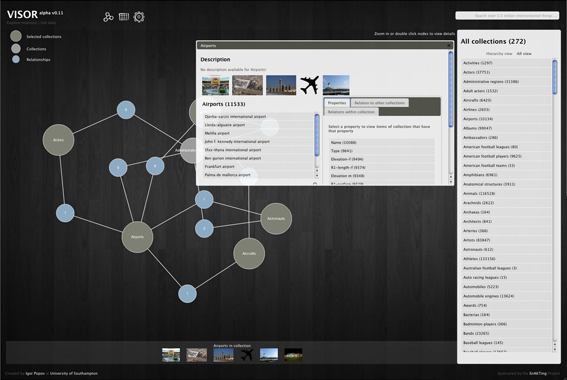
Visor
Visor is an data exploration interface for Wikipedia using data from DBPedia. Visor allows you to explore the DBPedia native ontology, view collections of data and develop tables using a user-friendly querying interface.
Publications
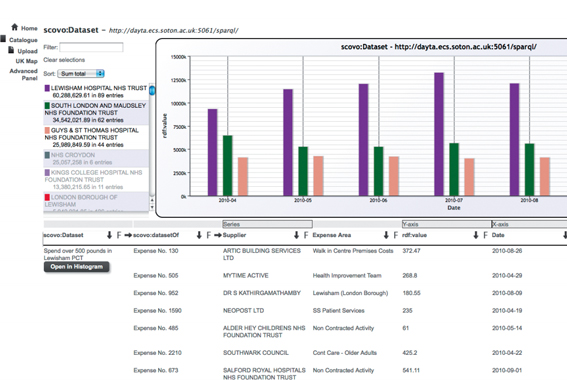
GEORDi
GEORDi is a generic browser based designed for end-users, those without technical skills, to discover, browse, navigate and support common sensemaking acctivites over distributed data sources.
Publications
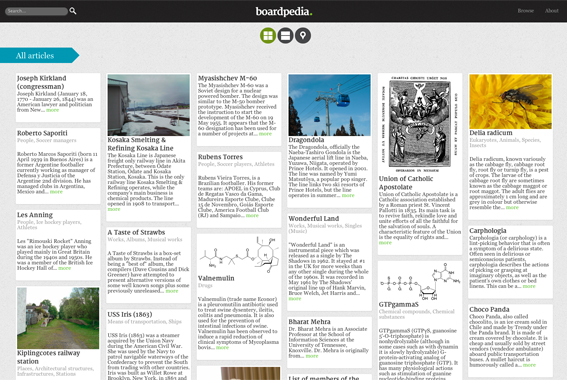
boardpedia
boardpedia is a Pinterest style browser for Wikipedia using data from DBPedia. It is implementated to be a easy-to-use, configurable faceted browser over SPARQL endpoints.
Demo
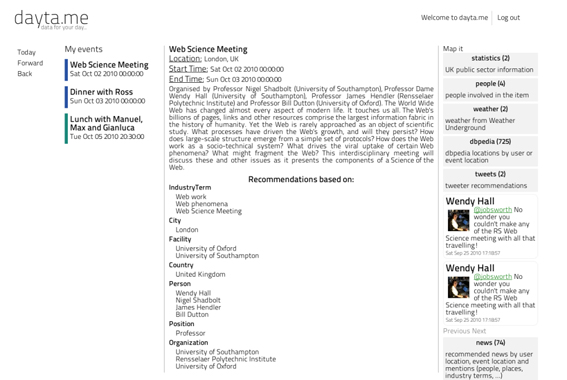
dayta.me
dayta.me recommends various data for your day based on events in your Google Calendar. It shows relevant news, tweets, transport data, important persons, statistical data and weather based on events and personal context (e.g. location). Browsing in dayta.me is extended by providing further recommendations are extendedon the initial set of recommended data.
Publications
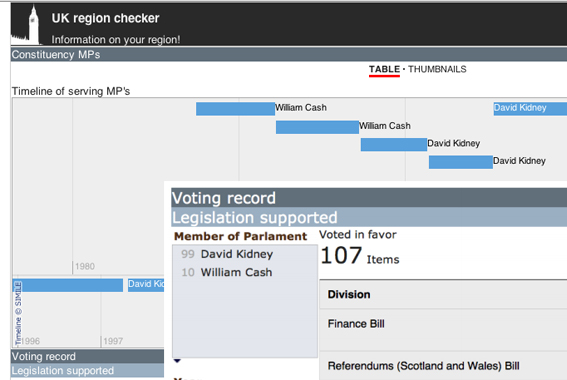
UK Region Checker
The UK Region Checker aggregates and visualises all available public information data just by inputing a post code.
Publications
Academic Publications
Smith, Daniel Alexander, Popov, Igor and schraefel, mc (2010) Data Picking Linked Data: Enabling Users to create Faceted Browsers. At Web Science Conference 2010, Raleigh, NC, USA, 26 - 27 Apr 2010.
schraefel, monica, Smith, Daniel Alexander, Popov, Igor, Van Kleek, Max and Shadbolt, Nigel (2010) Will this work for Susan? Challenges for Delivering Usable and Useful Generic Linked Data Browsers.
Omitola, Temitope, Koumenides, Christos L., Popov, Igor O., Yang, Yang, Salvadores, Manuel, Correndo, Gianluca, Hall, Wendy and Shadbolt, Nigel (2010) Integrating Public Datasets Using Linked Data: Challenges and Design Principles. At Future Internet Assembly, Ghent, Belgium, 16 - 17 Dec 2010.
Simperl E., Mochol M., Bürger T., Popov I., Achieving Maturity: the State of Practice in Ontology Engineering in 2009, 8th International Conference on Ontologies, Databases, and Applications of Semantics ODBASE, 2009.
Imtiaz A., Giernalczyk A., Bürger T., Popov I., A predictive framework for value engineering within collaborative knowledge workspaces, eChallenges Conference, 2009.
Imtiaz A., Bürger T., Popov I., Simperl E. Framework for Value Prediction of Knowledge-based Applications, ECONOM2009 Workshop, BIS 2009.
Simperl E., Popov I., Bürger T. ONTOCOM revisited: Towards accurate cost predictions for ontology development projects, ESWC 2009.
Popov I., Ruiz Moreno C., Bürger T., Simperl E. Use cases for cost benefit information in collaborative knowledge creation. Technical Report, ACTIVE EU-IST Project, 2009.
Popov I., Bürger T., Imtiaz A.,Simperl E. Deliverable 4.1.1: Preliminary predictive model for costs and benefits. Technical Report, ACTIVE EU-IST Project, 2009. Popov I. A Cost Model for Lightweight Ontologies: Adapting the ONTOCOM Model. Technical Report TR-08-08-09, University of Innsbruck.
Popov I. Comparative analysis of Learning Management Systems. Technical Report TR-06-02-03, University of Geneva.